

From Small-Scale to Big Data: Comparing PHP-Airflow, Snowflake-Python, and PySpark for ETL
Choosing the Right ETL Pipeline: PHP-Airflow vs. Snowflake-Python vs. PySpark
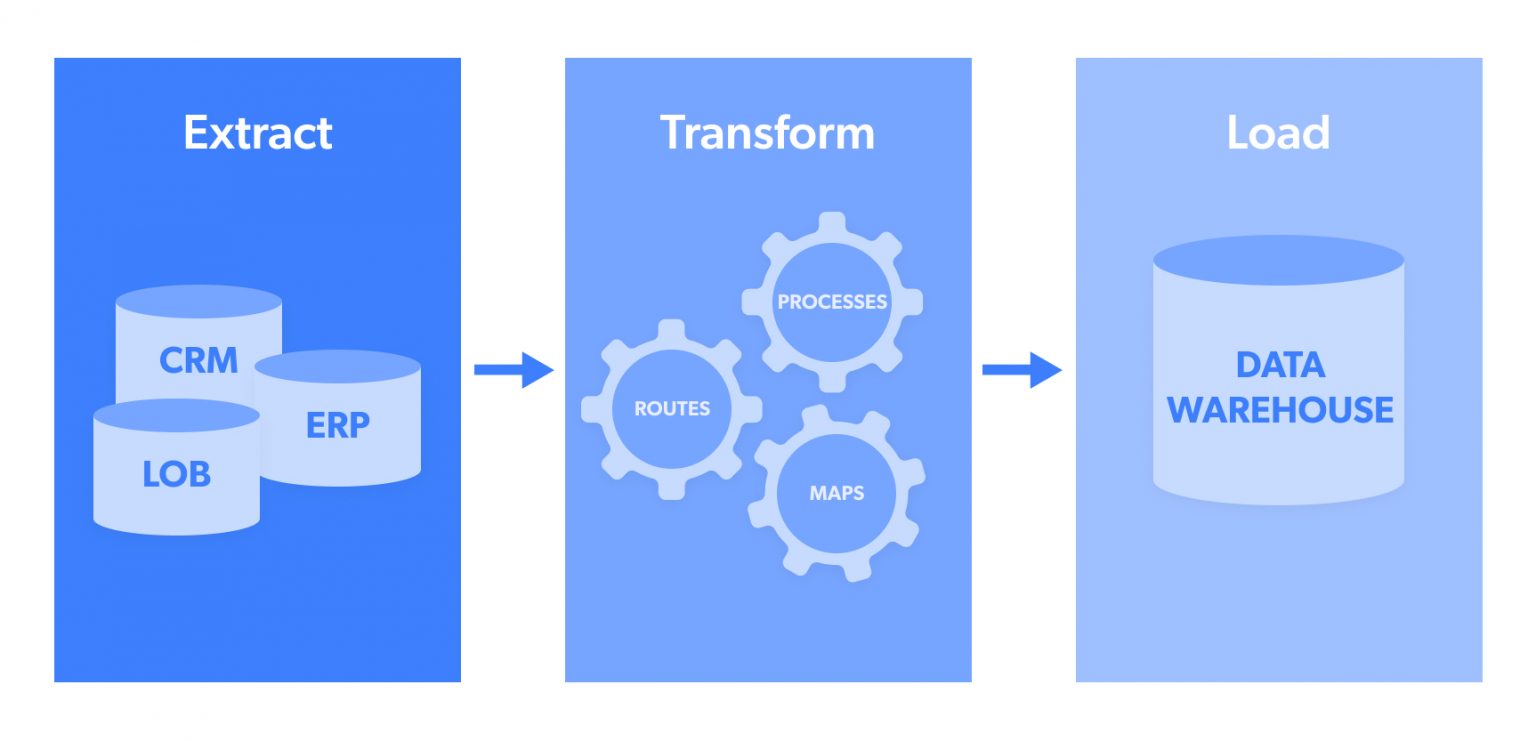
Caption: A conceptual diagram of an ETL pipeline.
In the world of data engineering, ETL (Extract, Transform, Load) pipelines are the backbone of data workflows. Whether you’re working with small datasets or big data, choosing the right tools and technologies is crucial for scalability, cost-effectiveness, and performance. In this blog, we’ll compare three popular approaches to building ETL pipelines: PHP-Airflow, Snowflake-Python, and PySpark. By the end, you’ll have a clear understanding of which approach fits your project’s needs.
1. PHP-Airflow Approach
Caption: A flowchart showing the PHP-Airflow workflow.
Technical Details
- Extract: PHP reads data from a local CSV file.
- Transform: PHP performs basic data cleaning (e.g., trimming whitespace, type conversion).
- Load: PHP inserts data into a MySQL table.
- Orchestration: Apache Airflow schedules and runs the PHP script.
Pros
- Low Cost: Open-source tools (PHP, MySQL, Airflow) with no licensing fees.
- Simple Setup: Easy to implement for small-scale projects.
- Lightweight: Minimal resource requirements for small datasets.
Cons
- Scalability: Not suitable for large datasets or distributed processing.
- Performance: PHP is not optimized for heavy data processing.
- Maintenance: Manual setup of Airflow and MySQL can be time-consuming.
Cost Estimate
- Infrastructure: Free (local machine or low-cost cloud VM).
- Tools: Free (PHP, MySQL, Airflow).
- Total Cost: ~$0 (if running locally) or ~$10–$20/month for a cloud VM.
Use Cases
- Small-scale ETL pipelines.
- Projects with limited budgets.
- Teams familiar with PHP and MySQL.
2. Snowflake-Python Approach
Caption: A diagram showing Snowflake-Python integration.
Technical Details
- Extract: Python reads data from a CSV file.
- Transform: Python performs data cleaning and transformation (e.g., trimming, type conversion).
- Load: Python loads data into Snowflake using the
snowflake-connector-pythonlibrary. - Orchestration: Apache Airflow schedules and runs the Python script.
Pros
- Scalability: Snowflake is designed for large-scale data warehousing.
- Performance: Snowflake’s cloud-native architecture ensures fast query performance.
- Ease of Use: Snowflake handles infrastructure, scaling, and maintenance.
- Integration: Seamless integration with Python and Airflow.
Cons
- Cost: Snowflake can be expensive for large datasets or high query volumes.
- Vendor Lock-in: Reliance on Snowflake’s proprietary platform.
- Learning Curve: Requires familiarity with Snowflake and cloud data warehousing.
Cost Estimate
- Snowflake: Pay-as-you-go pricing (~$2–$4 per credit; 1 credit ≈ 1 hour of compute).
- Example: ~$50–$100/month for small-scale usage.
- Infrastructure: Free (local machine) or ~$10–$20/month for a cloud VM.
- Tools: Free (Python, Airflow).
- Total Cost: ~$60–$120/month.
Use Cases
- Medium to large-scale ETL pipelines.
- Teams needing a cloud-based data warehouse.
- Projects requiring high performance and scalability.
3. PySpark Approach
Caption: A visual representation of PySpark’s distributed processing.
Technical Details
- Extract: PySpark reads data from a CSV file.
- Transform: PySpark performs distributed data cleaning and transformation.
- Load: PySpark writes data to a database (e.g., MySQL, PostgreSQL) or file system (e.g., HDFS, S3).
- Orchestration: Apache Airflow schedules and runs the PySpark job.
Pros
- Scalability: PySpark is designed for distributed processing of large datasets.
- Flexibility: Can work with various data sources and sinks (e.g., databases, cloud storage).
- Open Source: No licensing fees; integrates well with other open-source tools.
- Performance: Optimized for big data processing.
Cons
- Complexity: Requires setting up and managing a Spark cluster.
- Resource-Intensive: Needs significant compute and memory resources.
- Learning Curve: Requires familiarity with distributed systems and Spark.
Cost Estimate
- Infrastructure:
- Local cluster: Free (if using existing hardware).
- Cloud cluster: ~$100–$500/month (e.g., AWS EMR, Databricks).
- Tools: Free (PySpark, Airflow).
- Total Cost: ~$100–$500/month.
Use Cases
- Big data ETL pipelines.
- Teams with expertise in distributed systems.
- Projects requiring flexibility and scalability.
Comparison Table
| Feature | PHP-Airflow | Snowflake-Python | PySpark |
| Cost | ~$0–$20/month | ~$60–$120/month | ~$100–$500/month |
| Scalability | Low | High | Very High |
| Performance | Low | High | Very High |
| Ease of Setup | Easy | Moderate | Complex |
| Maintenance | Manual | Managed by Snowflake | Manual |
| Use Case | Small-scale projects | Medium to large-scale projects | Big data projects |
| Vendor Lock-in | None | Snowflake | None |
| Learning Curve | Low | Moderate | High |
Recommendations
PHP-Airflow:
- Best for small-scale projects with limited budgets.
- Ideal for teams familiar with PHP and MySQL.
Snowflake-Python:
- Best for medium to large-scale projects requiring a cloud data warehouse.
- Ideal for teams needing high performance and scalability without managing infrastructure.
PySpark:
- Best for big data projects requiring distributed processing.
- Ideal for teams with expertise in Spark and distributed systems.
Conclusion
Choosing the right ETL pipeline depends on your project’s scale, budget, and team expertise. Here’s a quick summary:
- PHP-Airflow is the most cost-effective but least scalable.
- Snowflake-Python offers a balance of scalability and ease of use but at a higher cost.
- PySpark is the most powerful and flexible but requires significant resources and expertise.
Evaluate your requirements and choose the approach that aligns best with your goals. Happy data engineering!